🚀 Challenge Rank Extension v2.1.0 : Official Firefox Support! 🏆
Hey everyone!
We’ve got a massive update for the Challenge Rank Extension (now officially on Firefox!) and some big quality-of-life improvements to the Daily Challenge Leaderboard.
If you’re tired of scrolling forever to find the top entries or want to know exactly why an image scored what it did, this one’s for you.
🌟 What’s New in the Extension (v2.1.0)
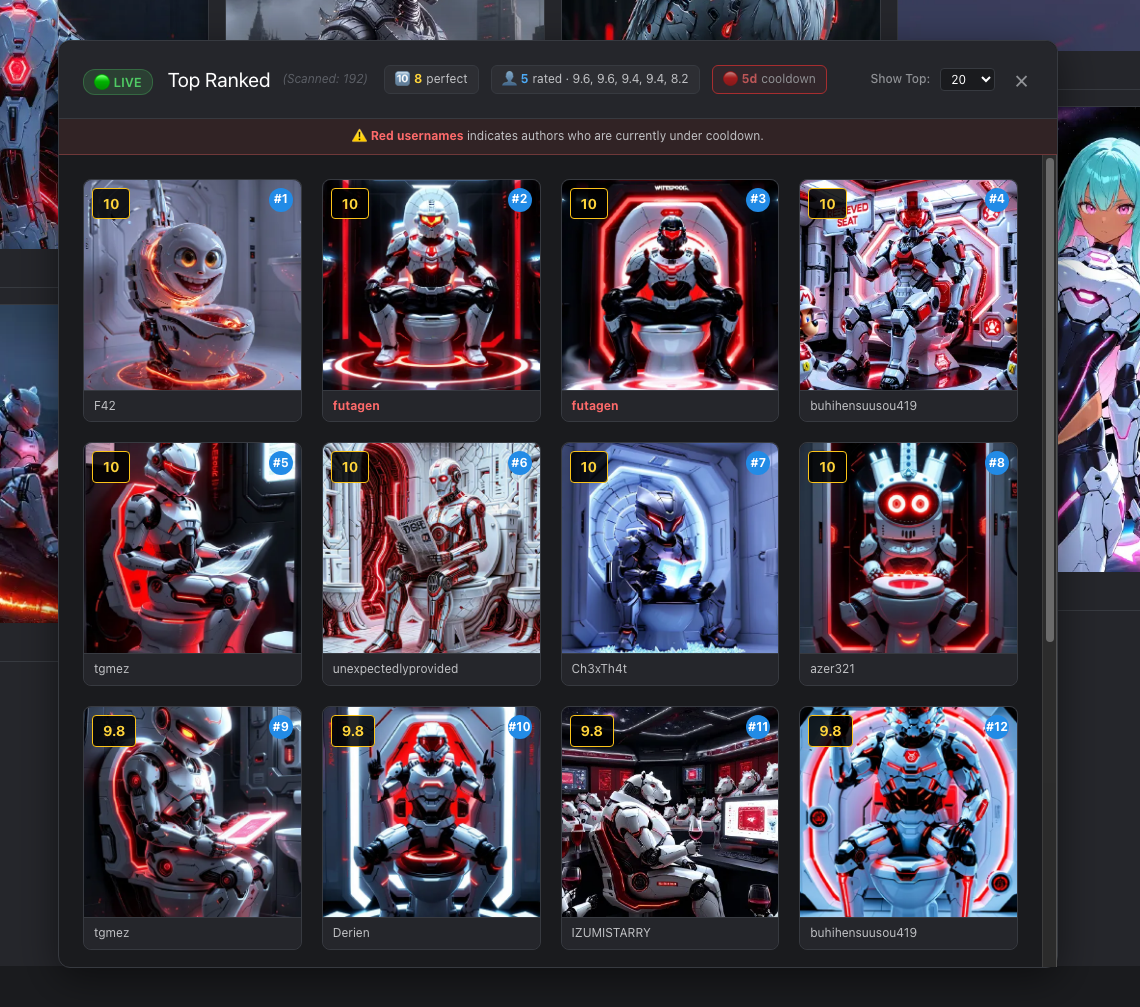
We’ve overhauled the overlay to give you way more context while you’re browsing:
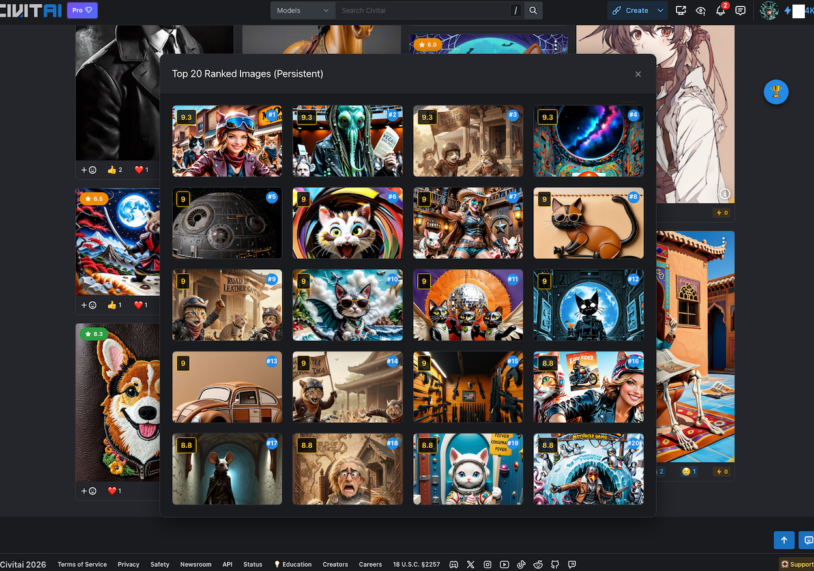
Gather in one place all the top rated images
-
⚙️ Custom Top N: You aren’t stuck with the Top 20 anymore. Toggle between the Top 10, 20, 50, or 100 directly from the dropdown.
-
📊 Live Stats: The header now tracks « Perfect 10s » in real-time( Cause we know that thoses days @CivBot tends to rate dozens images with a 10. It also detects your login and shows a quick summary of your own rated images.
-
🎨 Theme Hints: We added the specificTheme Elementsto the top of the overlay so you can see exactly what the judges were looking for without switching tabs( civitai didn »t disclose this informations anymore ) . -
⏳ Cooldown Tracking: To keep things transparent, the extension now syncs with the site to show who is currently on a winner’s cooldown. Their names will show up in 🔴 RED in the overlay ( may or may not working depends … ) Btw you have your Cooldown status displayed 100% time while logged.
-
Support news civitai websites : .com, .green, .red
-
🦊 Firefox is Live: We are officially verified! No more manual installs for Firefox users.
🌐 Leaderboard Site Upgrades
The UnOfficial site at ouinche.com/dailychallenge just got just updated :
Fully support new .com, .green, .red civitai websites
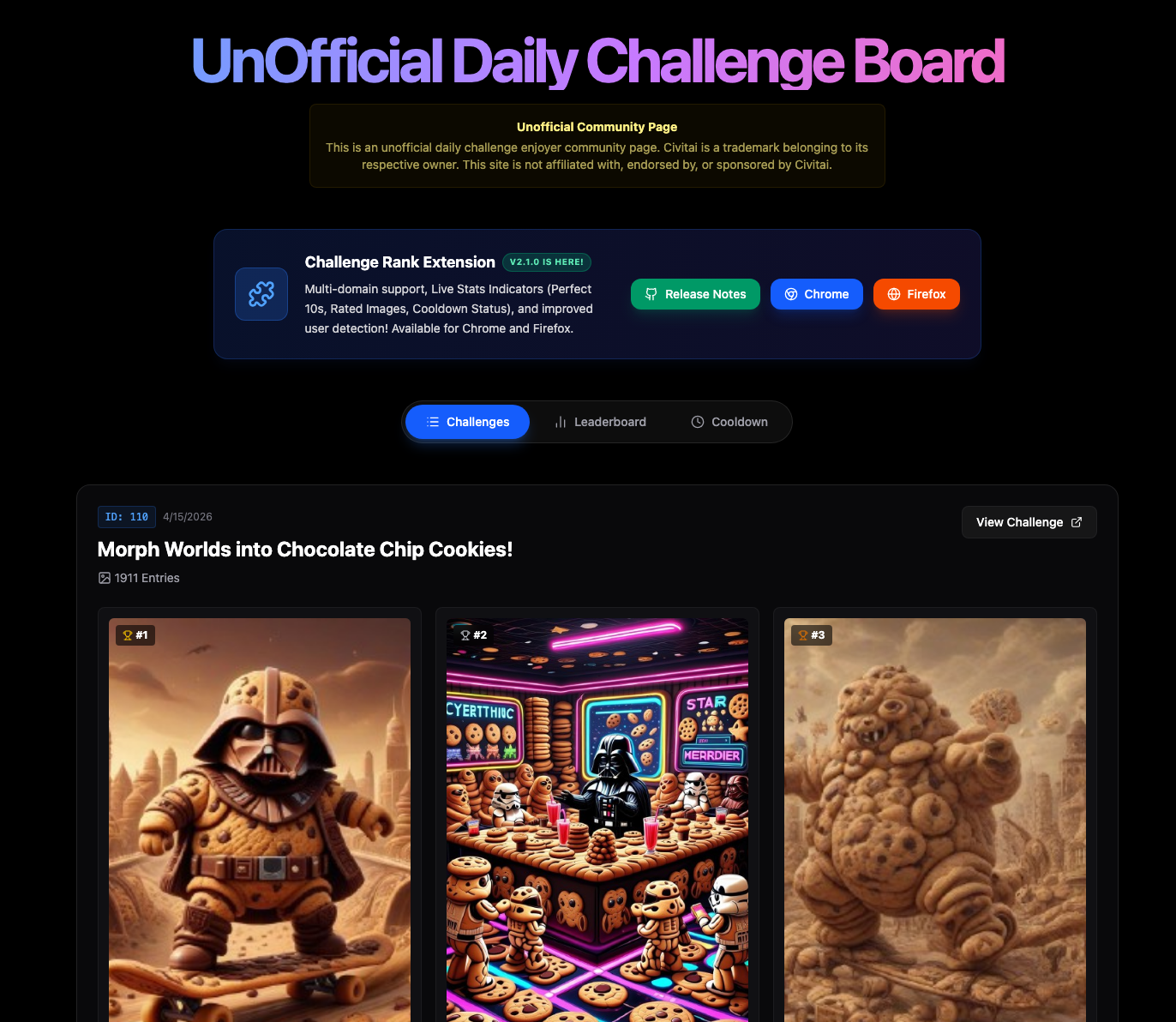
https://www.ouinche.com/dailychallenge/#leaderboard can now directly be linked from outside.
and now have Clickable User Profiles.
Just click any username on the leaderboard to pull up their full* history.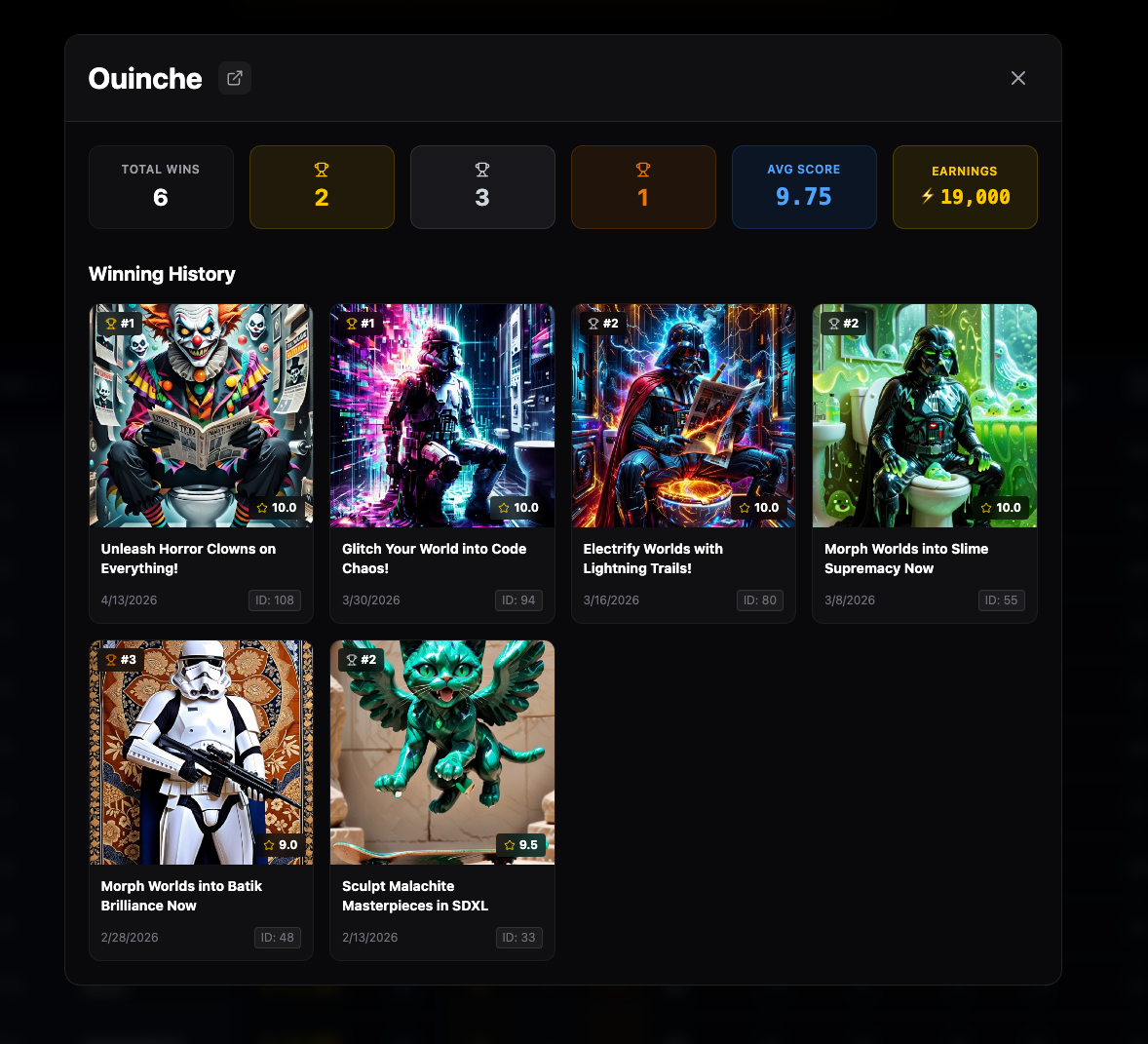 here my personnal records
here my personnal records
https://www.ouinche.com/dailychallenge/#cooldown can directly be linked to see who’s under cooldown
If you are found of Daily Challenge statistics, I recommend you to check https://dcd.legandor.com/ by Moonbear_AIArt
📥 Grab the Update
If you already have it, your browser should update it automatically soon. If you’re new:
-
🦊 Firefox: Download from the official Add-ons store
-
🌐 Chrome / Brave / Edge: Grab the latest release from GitHub (load it as an unpacked extension).
Good luck with the next challenge—hope to see some of you at the top of the leaderboard! ✨
Disclaimer: This is a community project and is not affiliated with or endorsed by Civitai.