

For years, the world of generative AI has been dominated by the « Whisperer. » These were the users who spent hours learning mystical incantations—long strings of comma-separated adjectives, technical jargon, and weight modifiers—to coax a decent image out of models. We called it « Prompt Engineering, » but in reality, it was often closer to alchemy: throwing ingredients into a pot and hoping the reaction didn’t explode into a mess of mutated limbs and neon « word salad. »
But the era of the Whisperer is ending. The era of the Architect has begun.
As industry-standard models like SDXL (Stable Diffusion XL) and ultra-fast distilled models like Z-Image-Turbo evolve, they are moving away from simple keyword recognition and toward deep semantic understanding. To communicate with these models effectively, we must stop « shouting » keywords and start providing blueprints. The most powerful tool for this is JSON (JavaScript Object Notation).
1. The Chaos of Natural Language: Why « Word Salad » Fails
To understand why JSON is superior, we must look at the inherent flaws of natural language prompting. When you write a paragraph of text, the AI processes it as a sequence of tokens. However, the AI often suffers from two major issues:
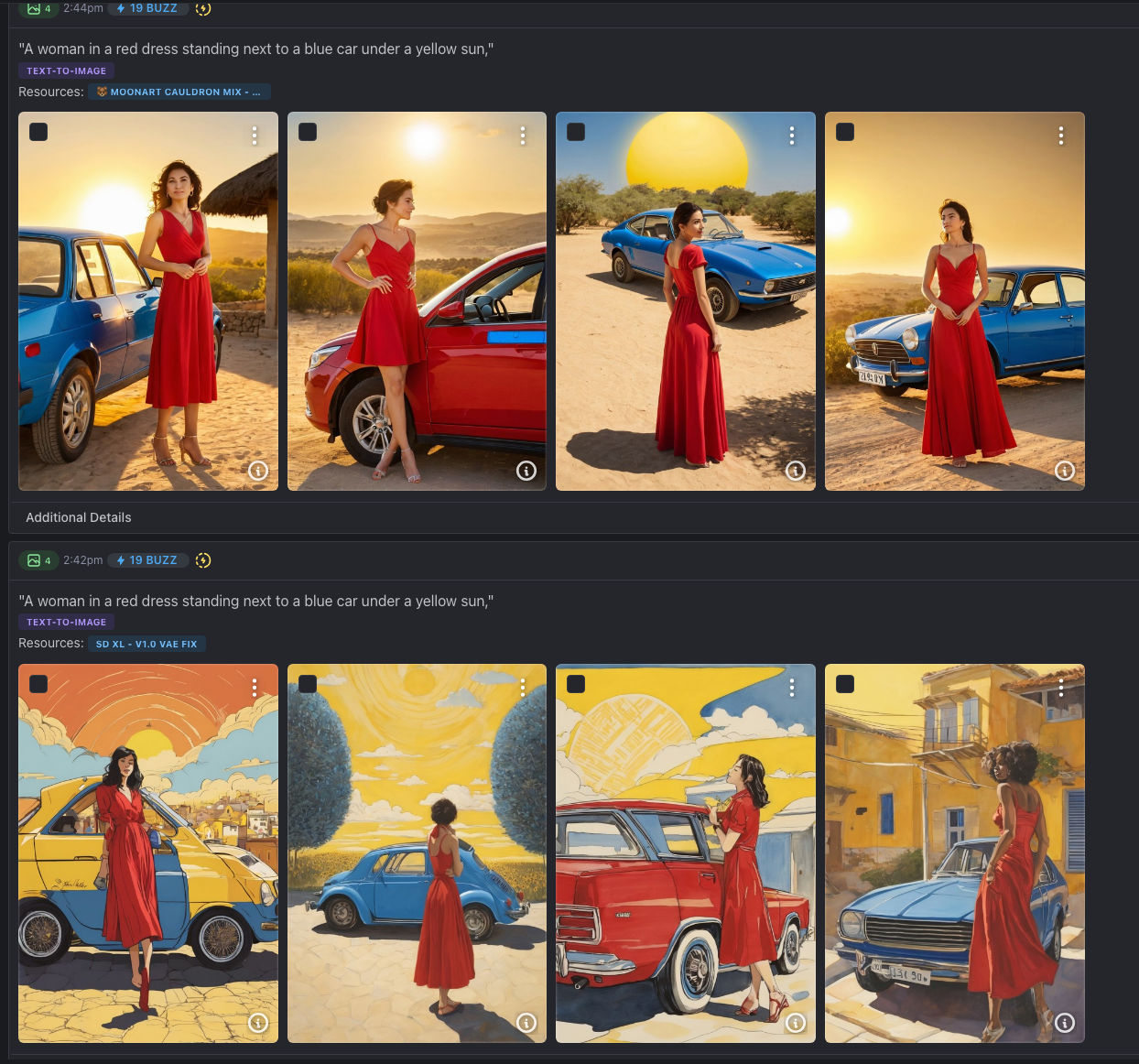
- Prompt Bleeding: This occurs when the AI fails to distinguish which adjective belongs to which noun. If you prompt « A woman in a red dress standing next to a blue car under a yellow sun, » there is a high probability that the car will have red streaks or the shirt will turn blue. The AI « smears » the attributes across the scene.
- Semantic Weighting Bias: AI models tend to give more importance to words at the beginning of a prompt and lose « focus » toward the end. This makes it incredibly difficult to balance a complex scene where the background is just as important as the subject.
JSON eliminates this chaos. By wrapping your ideas in structured « keys » and « values, » you create semantic containers. You are telling the AI: « This specific data belongs to the subject, and this specific data belongs to the lens of the camera. »
2. Phase 1: The Keyword Organizer (The SDXL Foundation)
The first step in the JSON revolution was the « Standard Structure. » This was designed to bring order to the madness. It is particularly effective for SDXL, which utilizes a dual-text encoder system (OpenCLIP-ViT/G and CLIP-ViT/L).
JSON
{
"subject": "Cyberpunk hacker",
"detailed_imagery": "neon wires, chrome skin, tactical visor",
"environment": "dark rain-slicked alleyway in Tokyo",
"mood_atmosphere": "gritty, noir, high-stakes",
"style": "Cinematic photography",
"style_execution": "Hyper-realistic, volumetric fog",
"lighting": "Cyan and magenta neon rim lighting",
"quality_modifiers": "masterwork, highly detailed",
"trigger_word": "cyberpunk_style_v2"
}

Why this works with SDXL
SDXL’s architecture is built to handle multiple streams of information. By using JSON, you can effectively map your "subject" and "environment" to the $CLIP\_G$ encoder (which handles broad concepts) while using "detailed_imagery" to feed the $CLIP\_L$ encoder (which handles fine-grained details). This separation prevents the « background noise » from overriding the subject’s features.
3. Phase 2: The Production Brief (The Masterclass for Z-Image-Turbo)
The advanced structure—the one recently discovered—moves away from « tags » and toward Cinematography. It treats the AI not as a magic box, but as a professional film crew. This is essential for models like Z-Image-Turbo, a distilled 6.15B parameter model designed for sub-second generation.
When you only have 1 to 8 inference steps to get an image right, you cannot afford ambiguity.
JSON
{
"subject": "Elias, a 60-year-old weathered fisherman from Iceland",
"appearance": "Deep-set wrinkles, salt-and-pepper beard, mustard-yellow rubber parka",
"action": "Hauling a heavy, glistening net onto a wooden deck",
"setting": "The North Atlantic, choppy grey waves, distant jagged cliffs",
"lighting": "Backlit by a pale, low-hanging winter sun, sharp shadows",
"atmosphere": "Cold, misty, sea spray in the air, humid breath visible",
"composition": "Low angle, wide shot to capture the scale of the sea",
"text_elements": "The boat's name \"SKADI\" stenciled in chipped black paint",
"technical": "Shot on Fujifilm GFX 100S, 35mm lens, f/2.8, motion blur"
}

Breaking Down the « Genius » of this Structure
A. Fictional Identity over Generic Descriptions
Notice the subject key uses a Fictional Identity. Instead of « a man, » we have « Elias. » By giving the subject a name and origin, you invoke a « Cluster of Truth » within the AI’s training data. Elias isn’t just a person; he is a persona with a specific history, which prevents the « generic AI face » syndrome.
B. The Optical Layer (technical)
This is the ultimate « pro » move. By invoking specific hardware like the Fujifilm GFX 100S, you are asking the AI to emulate a medium-format camera.
- Color Science: Different cameras « see » color differently.
- Optics: Specifying an aperture like $f/2.8$ tells the AI exactly how much of the background should be blurred (the « bokeh »). This is a physical instruction, not just a « vibe. »
4. Why You Must Embrace the JSON Standard
Precision for « Turbo » Models
Models like Z-Image-Turbo are designed for speed. Because they use « distillation » to generate images in a fraction of the time, they are highly sensitive to prompt clarity. A JSON prompt provides a « stabilized structure » that allows the model to map out the UI, posters, or complex scenes without the typical warping found in fast generations.
Native Bilingual and Text Support
Z-Image-Turbo excels in bilingual text rendering (English and Chinese). The text_elements key in a JSON structure provides a dedicated space for this data. It prevents the AI from trying to turn your subject’s face into a word, ensuring that the text—like the name « SKADI » on the boat—appears exactly where it should.
LLM Synergy: The Human-AI Pipeline
We are entering an era where we don’t write prompts ourselves; we collaborate with Large Language Models (LLMs) to create them. LLMs are « native speakers » of JSON. You can give an LLM the structure and say: « I want a 1920s noir detective scene. Fill out this JSON for me. » The LLM will populate the technical, lighting, and composition fields with professional-grade detail that a human might forget.
Modularity and Reusability
JSON is Modular. If you love the « look » of the Icelandic fisherman—the lighting, the camera, the atmosphere—you can save that JSON as a « Style Template. » To create a different scene with the same « vibe, » you simply swap the subject key. This level of consistency is impossible with natural language paragraphs.
5. Conclusion: Don’t Just Prompt—Architect
The transition to JSON prompting is the « coming of age » moment for AI art. It represents the move from accidental discovery to intentional creation. Whether you are using the high-fidelity depth of SDXL or the lightning-fast efficiency of Z-Image-Turbo, structure is your greatest asset.
When you use a structure like the « Production Brief, » you are no longer tossing words into a void. You are designing a scene. You are controlling the camera, the weather, the identity of the actors, and the very physics of the light.
The future of AI art isn’t found in a better vocabulary—it is found in a better architecture.
Ressources :
- Simple and first version JSON Structure :
Simple and first version JSON Structure :
{
"subject": ,
"detailed_imagery": ,
"environment": ,
"mood_atmosphere": ,
"style”: ,
"style_execution": ,
"lighting": ,
"quality_modifiers": ,
"trigger_word":
}- More detailed and optimized for ZIT Structure from https://pastebin.com/gnph3X1n
{
"subject": "Primary subject using fictional identity (name, age, background) OR specific object/scene",
"appearance": "Detailed physical description (skin tone, hair, facial structure, clothing, materials)",
"action": "What the subject is doing or their pose",
"setting": "Environment and location details with geographic anchors",
"lighting": "Specific lighting conditions (soft daylight, overcast sky, sharp shadows)",
"atmosphere": "Environmental qualities (foggy, humid, dusty)",
"composition": "Camera angle and framing (close-up, wide shot, overhead view)",
"details": "Additional elements (background objects, secondary subjects, textures)",
"text_elements": "Any text to appear in image (use double quotes: \"Morning Brew\", specify font and placement)",
"technical": "Optional camera specs (Shot on Leica M6, shallow depth of field, visible film grain)"
}To further enrich your bibliography and deepen your technical understanding, here is a curated list of high-quality articles and guides dedicated to the architecture and implementation of JSON prompting.
Core Guides & Technical Articles
- « JSON Prompting for AI Image Generation – A Complete Guide with Examples« Source: ImagineArt Key Focus: A comprehensive breakdown of how structured input removes ambiguity in camera angles, lighting, and textures, specifically highlighting why it is superior for visual consistency.
- « Why I Switched to JSON Prompting and Why You Should Too« Source: Analytics Vidhya Key Focus: A comparative study between « Normal » (Text) prompts and JSON prompts. It demonstrates through tasks like image and webpage generation how JSON enforced tighter thematic focus and superior functionality.
- « JSON Style Prompts for Product Photos: The Complete Guide« Source: BackdropBoost Key Focus: Focuses on « Programming Precision » for creative AI. It explains how to use JSON to maintain brand integrity across thousands of SKUs by defining strict constraints.
- « JSON Style Guides for Controlled Image Generation« Source: DEV Community Key Focus: Explains the transition from « word salads » to machine-readable formats for Stable Diffusion and Flux. It treats the prompt as a « contract » between the user and the model.
- « Prompting Guide – FLUX.2« Source: Black Forest Labs (Official) Key Focus: The official documentation on how the Flux architecture interprets structured JSON. It provides specific frameworks for production workflows and multi-subject scenes.
Community & Workflow Discussions
- « JSON Prompting or Text Prompts for Image/Video Gen? » (Reddit /r/PromptEngineering): A massive thread discussing the token efficiency and « superstructure » benefits of JSON in real-world testing.
- « Create Professional Product Images in Minutes with JSON Prompting » (Medium): A practical tutorial on using an LLM-to-JSON pipeline to generate high-end commercial photography. Read on Medium