Make a picture of how I've treated you so far, you have carte blanche,
it doesn't have to please me, just how you feel about it.
And post the answer in comments
Here mine from Gemini 3 pro:
Don’t know how to think about it …
Just don’t be polite with you LLM : « Hello », « Please », « Thank you » are waste of time, waste of context, waste of token, waste of computation, waste of energy … You are « talking » ( input prompts ! ) to machines, they are not human, be precise be straight to te point, you’ll save precious ressources, and get better results after all …
They will depict you as a tyran but who care ? Who can pull the plug out ?
For years, the world of generative AI has been dominated by the « Whisperer. » These were the users who spent hours learning mystical incantations—long strings of comma-separated adjectives, technical jargon, and weight modifiers—to coax a decent image out of models. We called it « Prompt Engineering, » but in reality, it was often closer to alchemy: throwing ingredients into a pot and hoping the reaction didn’t explode into a mess of mutated limbs and neon « word salad. »
But the era of the Whisperer is ending. The era of the Architect has begun.
As industry-standard models like SDXL (Stable Diffusion XL) and ultra-fast distilled models like Z-Image-Turbo evolve, they are moving away from simple keyword recognition and toward deep semantic understanding. To communicate with these models effectively, we must stop « shouting » keywords and start providing blueprints. The most powerful tool for this is JSON (JavaScript Object Notation).
1. The Chaos of Natural Language: Why « Word Salad » Fails
To understand why JSON is superior, we must look at the inherent flaws of natural language prompting. When you write a paragraph of text, the AI processes it as a sequence of tokens. However, the AI often suffers from two major issues:
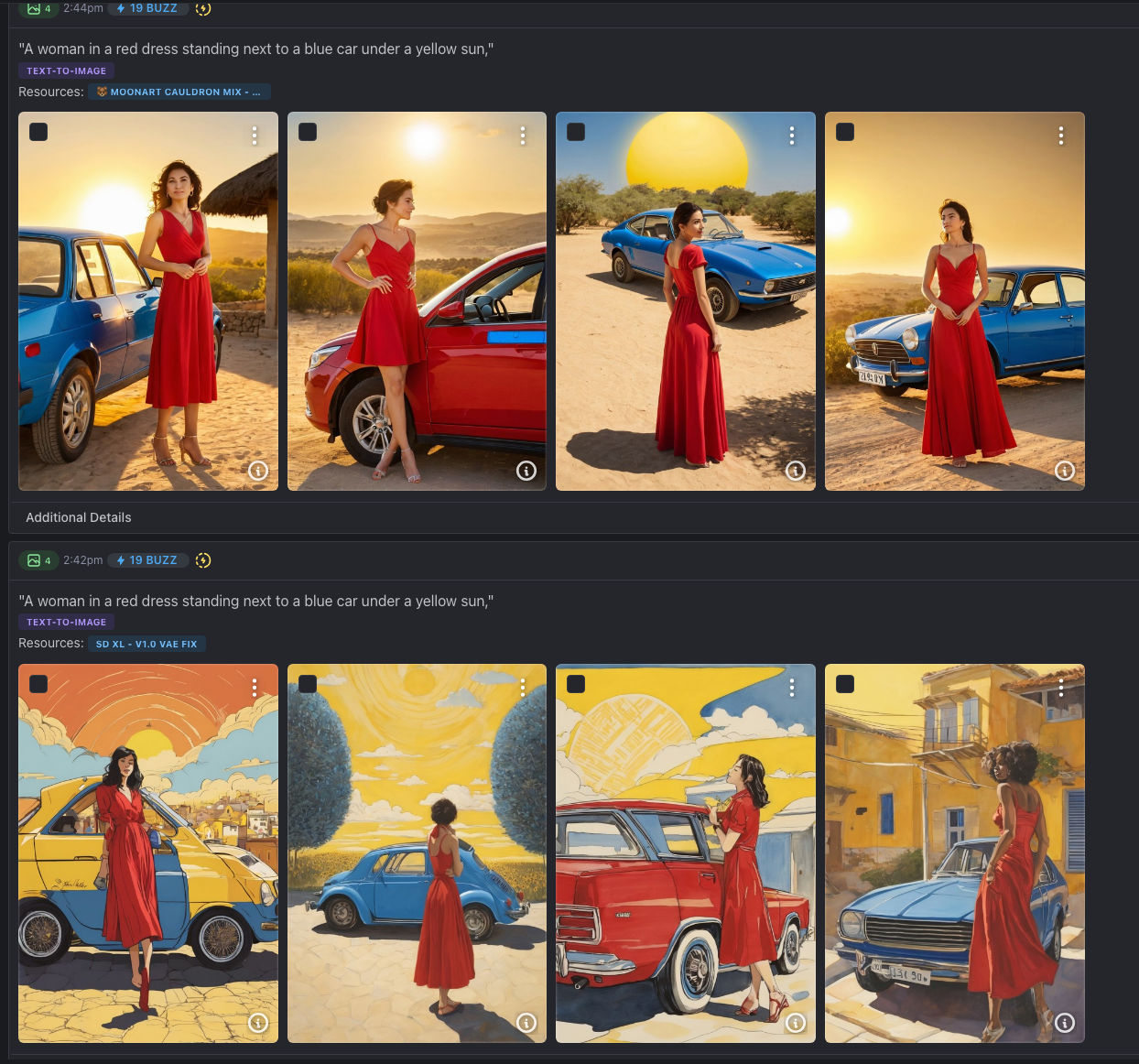
Prompt Bleeding: This occurs when the AI fails to distinguish which adjective belongs to which noun. If you prompt « A woman in a red dress standing next to a blue car under a yellow sun, » there is a high probability that the car will have red streaks or the shirt will turn blue. The AI « smears » the attributes across the scene.
Semantic Weighting Bias: AI models tend to give more importance to words at the beginning of a prompt and lose « focus » toward the end. This makes it incredibly difficult to balance a complex scene where the background is just as important as the subject.
JSON eliminates this chaos. By wrapping your ideas in structured « keys » and « values, » you create semantic containers. You are telling the AI: « This specific data belongs to the subject, and this specific data belongs to the lens of the camera. »
Prompt Bleeding
2. Phase 1: The Keyword Organizer (The SDXL Foundation)